std::tuple is not a zero-cost abstraction, stackoverflow的討論Transformative AGI by 2043 is <1% likely: 這篇文章是提交給 Open Philanthropy AI Worldviews Contest 的作品. 在文章中, 我們評估了到2043年實現變革性人工通用智能(AGI)的可能性, 並發現其可能性小於1%. 論點如下:
- 標準很高: 比賽中所定義的AGI - 也就是能以人類成本或更低的成本執行幾乎所有有價值任務的AI - 我們稱之為變革性AGI, 這個標準比僅僅在AI方面取得巨大進步, 或者甚至明確地獲得昂貴的超人類AGI或廉價但不均勻的AGI要高得多.
- 需要多個步驟: 到2043年實現變革性AGI的可能性可以分解為許多必要步驟的聯合概率, 我們將其分為軟件, 硬件和社會政治因素類別.
- 沒有步驟是保證的: 對於每個步驟, 我們估計了在先前的步驟成功的條件下, 到2043年成功的概率. 許多步驟受到時間表的嚴重限制, 我們的估計範圍從16%到95%.
- 因此, 可能性很低: 將累積的條件概率相乘, 我們估計到2043年實現變革性AGI的可能性為0.4%. 要達到>10%的可能性似乎需要不合理的高概率, 甚至3%的可能性也似乎不太可能. 透過深思熟慮地應用累積條件概率方法於此問題, 得出的概率值低於通常所假定的. 此框架有助於列舉人類朝著實現變革性AGI但未能完全實現的許多未來情景.
土蝦 真有趣的食物


C:\Users\Your_User_Name\AppData\Local\Google\Chrome\User Data\Default\Network, Firefox + Windows 10: C:\Users\Your_User_Name\AppData\Roaming\Mozilla\Firefox\Profiles, Edge + Windows 10: C:\Users\Your_User_Name\AppData\Local\Microsoft\Edge\User Data\Default\Network, Opera + Windows 10: C:\Users\Your_User_Name\AppData\Roaming\Opera Software\Opera Stable\Network, Chrome + MACOS: /Library/Application Support/Google/Chrome/Profile 2/Cookies, FireFox + MACOS: /Library/Application Support/Firefox/Profiles/xxxxxx.default-release/cookies.sqlite, Edge + MACOS: /Library/Application Support/Microsoft Edge/Default/Cookies, Opera + MACOS: /Library/Application Support/com.operasoftware.Opera/Cookies, Ubuntu: ~/.config/google-chrome/Default/Cookies, 這個資訊主要是為了能讓 yt-dlp 能在Linux下面下載 twitter 的影片. 我習慣用 tlink=twitter_url + yt-dlp --cookies-from-browser chrome $tlink 去下載檔案.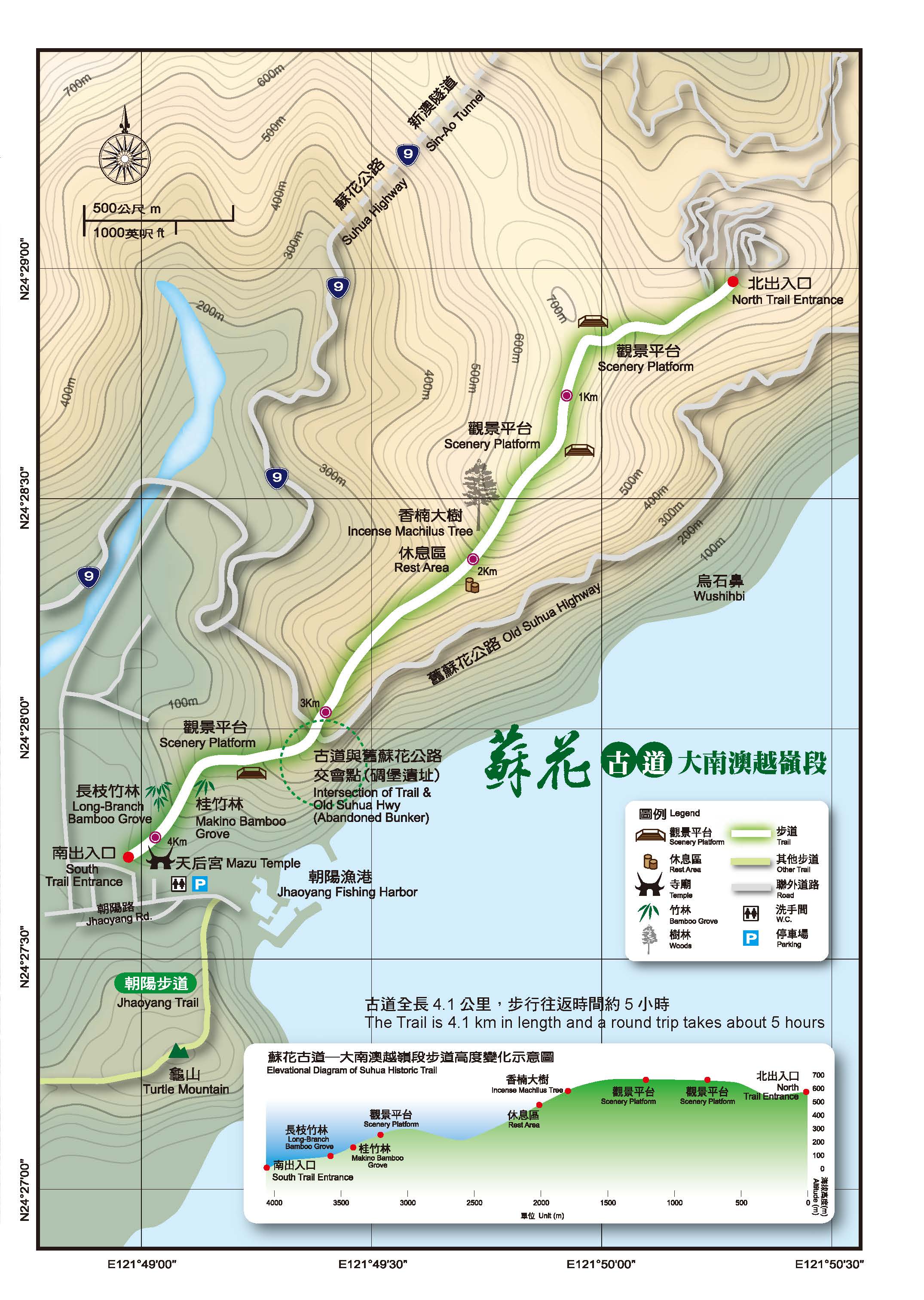
Some background on terminology:
這個討論的基本問題是 Rust 決定使用"無堆疊協程(stackless coroutine)"的方法來實現用戶空間的並發性. 在這個討論中有很多術語被提及, 而不熟悉它們都是合理的.
首先, 我們需要明確的概念是這個功能的目的: "用戶空間的並發性(user-space concurrency)". 主要的作業系統提供了一套相當相似的介面來實現並發性: 你可以生成線程(threads), 並在這些線程上使用系統呼叫(syscalls)來執行IO, 這會阻塞該線程直到它們完成. 這些介面的問題是它們涉及到某些開銷, 當你想要達到某些性能目標時, 這些開銷可能會成為限制因素. 這些開銷主要有兩方面:
在內核和用戶空間之間的上下文切換(context-switching)在CPU週期方面是昂貴的.
作業系統的線程有一個大的預分配堆疊(stack), 這增加了每線程的記憶體開銷.
這些限制到某個程度是可以接受的, 但對於大規模並發的程序, 它們就不適用了. 解決方案是使用非阻塞IO介面, 並在單個作業系統線程上安排許多並發操作. 這可以通過程序員"手動"完成, 但現代語言通常提供了便利設施來使這更容易. 從抽象角度看, 語言有某種方法將工作劃分為任務(tasks), 並將這些任務安排到線程上. Rust的系統就是透過async/await來實現的.
在這個設計空間的第一個選擇軸是協作(cooperative)和抢占式(preemptive)排程之間的選擇. 任務是否必須"協作式"地將控制權交還給排程子系統, 或者它們可以在運行的某個時候被"抢占式"地停止, 而任務不知道這一點?
在這些討論中經常被提及的一個術語是協程(coroutine), 並且它有些自相矛盾的用法. 協程是一個可以暫停然後稍後恢復的函數. 很大的模糊區是, 有些人使用"協程"這個術語來指具有顯式語法用於暫停和恢復它的函數(這對應於協作式排程的任務), 有些人用它來指任何可以暫停的函數, 即使暫停是由語言運行時隱式執行的(這也包括抢占式排程的任務). 我更喜歡第一個定義, 因為它引入了某種有意義的區別.
另一方面, Goroutines是Go語言的一個功能, 它使得並發, 抢占式排程的任務成為可能. 它們具有與線程相同的API, 但是它是作為語言的一部分實現的, 而不是作為作業系統原始概念, 在其他語言中它們通常被稱為虛擬線程(virtual threads)或綠色線程(green threads). 所以按照我的定義, goroutines不是協程, 但其他人使用更廣泛的定義並說goroutines是一種協程. 我會將這種方法稱為綠色線程(green threads), 因為這一直是Rust中使用的術語.
這個選擇的第二個軸是在有堆疊的協程(stackful coroutine)和無堆疊的協程(stackless coroutine)之間選擇. 有堆疊的協程具有程序堆疊, 就像作業系統的線程具有程序堆疊一樣: 當協程的一部分被調用時, 它們的框架被推到堆疊上; 當協程產生時, 堆疊的狀態被保存, 以便可以從相同的位置恢復. 另一方面, 無堆疊的協程以不同的方式存儲它需要恢復的狀態, 如在續行(continuation)或在狀態機(state machine)中. 當它產生時, 它正在使用的堆疊被接管它的操作所使用, 當它恢復時, 它重新控制堆疊, 並且該續行或狀態機用於從它離開的地方恢復協程.
與async/await(在Rust和其他語言中)相關的一個經常提出的問題是"函數著色問題(function coloring problem)" - 一個抱怨說, 為了得到async函數的結果, 你需要使用不同的操作(如等待它), 而不是正常調用它. 綠色線程(green threads)和有堆疊的協程機制都可以避免這個結果, 因為它是用來指示正在管理協程的無堆疊狀態的特殊語法(具體取決於語言).
Rust的async/await語法是無堆疊協程機制的一個例子: 一個async函數被編譯成一個返回Future的函數, 而那個未來是用來在它放棄控制時存儲協程的狀態的. 這個討論中的基本問題是, Rust是否正確地採用了這種方法, 或者它應該採用更像Go的"有堆疊"或"綠色線程"方法, 理想情況下不用明確的語法來"著色"函數.
3d-to-photo: 3D to Photo is an open-source package by Dabble, that combines threeJS and Stable diffusion to build a virtual photo studio for product photography. Load a 3D model into the browser and virtual shoot it in any kind of scene you can imagine
服務靜態媒體資源,
在七種語言中運行應用程式碼.
Unit 將現代應用程式堆疊的多層壓縮成一個強大, 連貫的解決方案, 專注於性能, 低延遲, 和可擴展性. 它被設計為任何網絡架構的通用構建塊, 無論其複雜程度如何, 從企業規模部署到你寵物的主頁.
它的原生RESTful JSON API允許動態更新, 零中斷並具有靈活的配置, 同時它的開箱即用的生產力可靠地擴展到生產級的工作負載. 我們通過包含多個程序的複雜, 異步, 多執行緒架構實現了這一點, 以確保安全性和健壯性, 同時充分利用了今天的運算平台.
[](https://www.youtube.com/embed/VIDEO_ID)Virgil Dupras想法挺特別的, 他覺得2030世界供應鏈會崩潰, 所以需要一個能夠在洗衣機晶片上面跑的作業系統. 嘖嘖嘖! 挺帥的. Collapse OS — what makes collapse inevitable and imminent, Collapse OS — Why?Embraces native HTML form validation
Out of the box integration with UI libraries
Small size and no dependencies
Support Yup, Zod, AJV, Superstruct, Joi and others
repo
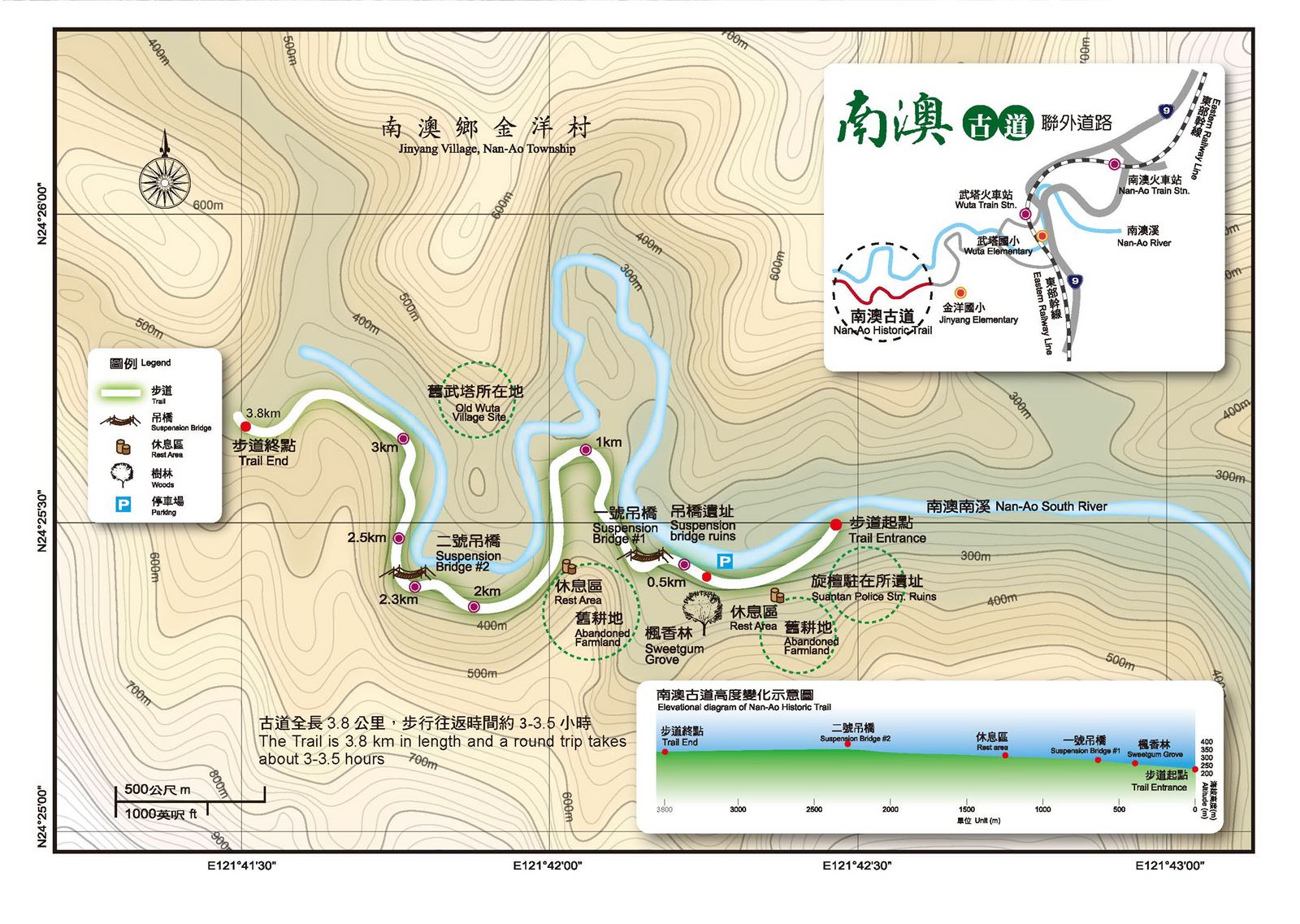
 - 區間快速 4024次 - 超級划算, 假日買不到對號車票時的救星,北花不用三小時,還只收你255元
- 區間快速 4024次 - 超級划算, 假日買不到對號車票時的救星,北花不用三小時,還只收你255元
氫氟酸 - 酸
聚四氟乙烯 - 盾


